Once Upon a Time there was a company called Base7Booking that by the beginning of 2016 it was supporting around 1200 databases on MySQL 5.5, each corresponding to single client, each of them with a different db user and all of them with the same database structure.
The situation of the database at that time was like:
- Most of the table names were in French
- Database was not relational at all
- A significant amount of columns and tables were not in use anymore
- Data was partially corrupt, inconsistent or even unlinked
Due to those fact and having ahead of the company a big potential growth coming from a big investment we decided to migrate all of that to Postgres trying to provide to our client databases the best consistence, performances and stability. These were the list of achievement we wanted to accomplish after the migration:
- Migrate every client database at same time into Postgres
- Provide consistency turning into a relational database
- Cleanup and repair corrupt, insistence and unlinked data
- Standardize table and column names using English as main language for it
- Minimize the migration time to reduce the time clients were not going to be able to use the product (downtime)
- Design a fail-over process to restore previous version back with the least consequences to final users.
Then, once goals were all down in paper and after many discussing about possible repercussion of a wrong migration process we decided to go ahead with it.
Step1: Migrate database from MySQL to Psql
The first phase of the migration is plenty clear, migrate everything from MySQL to Postgres, but there were many more sub steps to carry on before fulfilling this. First of all, decide which language to use for performing the migration, and for that we need to split this step into smaller sub-steps and then look up for the language which provides the best tools to carry this through.
Those steps where:
Those steps where:
- Create client databases with the new structure in Postgres
- Support previous database structure, this time on Postgres therefore we reduce to the minimum the amount of change we will need to apply in the code
- Migrate every database data and indexes besides cleaning it and providing consistency to it.
- Re-create the same database users to maintain the same logic we had in previous version.
Which are the requirements we get out of that? What will the language we choose to perform?
- Support MySQL and Postgres connection drivers.
- It has to be good managing text, encoding and regex to manipulate the data.
- It will need to get along with OS because we will likely need to interact with the filesystem.
- We will need to improve the speed till the top, so probably it will need to support multithreading and multiprocessing.
Create client databases with the new structure in Postgres
Beforehand this might look easy, basically we need to migrate design a mapping which converts previous database model to new one, redefining table names, column names, column types, indexes, constraints and adding foreign keys which makes our database relational. Therefore we decided to implement a easy JSON structure which defines every conversion rule, just if something was going to be manipulated during the process it will be written here. One of the examples of that was :
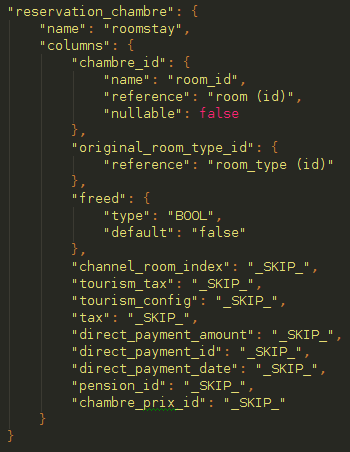
Moreover there are types which doesn’t exist in Postgres as MEDIUMINT, TINYINT.... apart of that there were additional problems coming from a bad database design as the use of TINYINT(1) or even SMALLINT(1) instead of BOOL, and on top of that Postgres use a different syntax for special cases as current_timestamp and so on. Then we defined a bunch of small rules which covered all those cases:
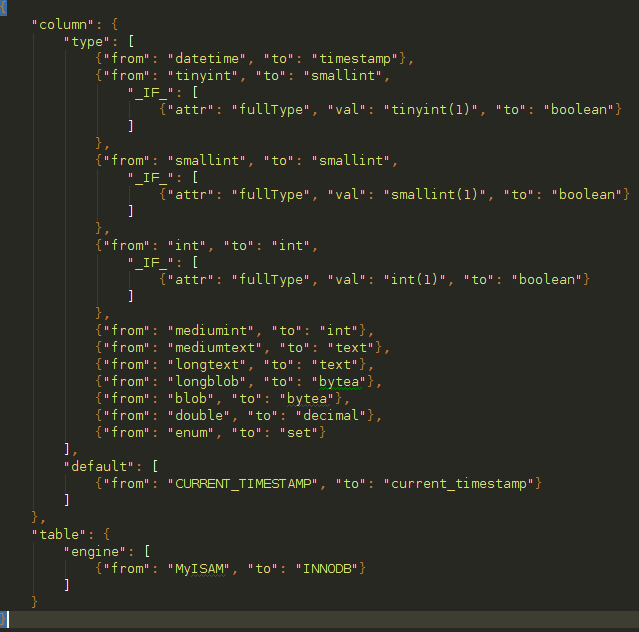
As a result from those rules we ended up with a intermediate JSON file which, finally, contains the whole database mapping, every table and columns and their new types, names, constrains, etc.
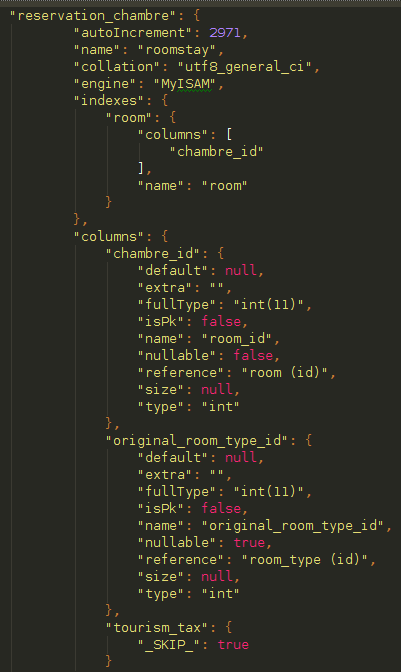
Only missing thing would be to read the current db structure of MySQL databases from the INFORMATION SCHEMA and parse it using the above above JSON.
Migrate and fit data into new database
Derived from previous database conversion, we will need to apply change to data along with changes we applied to the model. That mean we won’t be able to just run a single mysqldump then convert couple of syntax issues and import it into Postgres, instead we will need to process every single row, every single column and value to validate it, convert it and even redefine it as it was the case of dates (because we were moving to UTC).
That was carried in two simple steps:
- Cleanup values: It was a bunch of rules which were checking one by one the former type of each value and its new one and converting them, a few example you have it in here:
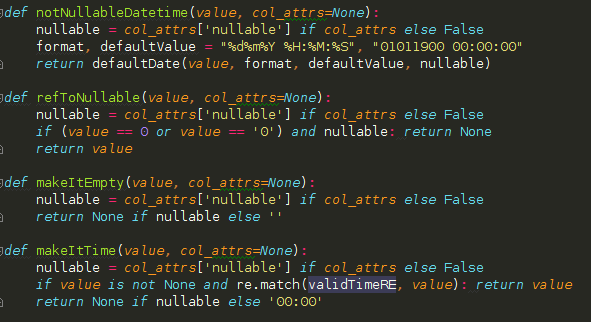
- Cleanup rows: Due to the new relational database we would need to remove the rows which became over the time unlinked or inconsistent. For that it was enough with a battery of sql queries which were generated automatically and they were launched at the beginning of each table migration.
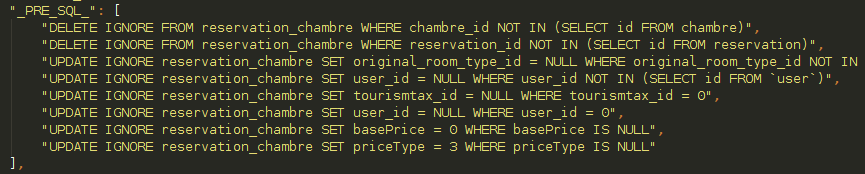
Maintaining former database structure
As it was said above, one of the main requirements is to avoid big changes in the code of the main app of Base7, due to it we were forced to find out a way to keep both versions running in parallel with the least effort.
Now is when one of the main reasons to take Postgres as our new database server. Postgres allows the use of Views(include link) supporting INSERT, UPDATE and DELETE meanwhile the relation between views and tables are one to one, ....isn’t it awesome?
Then another issue came up, some table were not renamed but their columns did and we cannot have views and table with the same name under same database, but Postgres also provides you with a solution for it, schemas(include link), schemas allow you to have separate database structure within same actual database, it is like a kind of namespace for database elements.
Here it is an example of how we created those views:
Notice we have at the end every column which are not longer needed, otherwise it won’t work because empty data values cannot be automatically parsed if they are in the middle.
Moreover we also implemented another small tool which can double check in the migrated data was moved without missing any single row, or getting wrong encoded text, or values were still matching. Thanks to this tool we realized of some conversion problems in booleans and encoding issues were the text was migrated in ASCII instead of UTF8.
If you are interested in knowing more about it or you are thinking on migrating your current database from MySQL to Postgres we open sourced the tool here: https://github.com/ggarri/mysql2psql
Step2: Validate and adjust product to use Psql
Once data was moved within Postgres lands, it was time to upgrade our main application to point to the new database in Postgres and see what happens. At first, and as it was expected after updating our config files and use Postgres connector nothing was working, it was time to monitor logs and fix errors.
To get the app loading it was as simple as update an insert sql statement to use “true or false” instead of “1 o 0”, then it was when I realized how tolerant is MySQL in compare with the Super Strict Postgres, at that time I realized it wasn’t going to be that easy as I thought to adjust the code to use Postgres. Here you have few of the issues you might run into if you decide to migrate from MySQL to Postgres:
- Postgres doesn’t support HAVING conditions using ALIASES
- Postgres forces the use of aggregation operation on every column which is not part of the GROUP BY
- Postgres doesn’t support operation between values of different types
- Postgres uses a different syntax, so IFNULL, CONCAT, DATE_ADD....many other are not available anymore
That was going to take time, but how was I going to find every glitch, by hand? one by one? Are we really going to test every single functionality under every single scenario to identify each of the lines of code we would need to modify? The answer was clear, NOT!!! We need to automatize that, how? Python ! Time to develop another tool.
The tool we decided to implement was going to replay the traffic of every single user for a period of 2-3 days, outcoming same response outputs, including views, and ending with both version of database, mysql and postgres with same status. If we could achieve that we may highly ensure that our app is running decently with Postgres and it won’t cause major issues to our clients.
These were the steps we had to do to get that tool running:
- Save traffic of our clients
- Replay traffic across both app versions
- Compare outputs
- Compare final status of databases
Save traffic of our clients
There are many possible ways to get this, you could?
- Use third party tools as gor (https://github.com/buger/gor),
- Install external plugins to Nginx as HttpGzipModule or using Reverse Proxying
- Create a separate file where we log every request and all the information it will be required to replay the same request.
We took the third option because the other two options were quite intrusive and they might interfere at the normal use of our app because in both cases they were going to be in between our users request and our app, so the less harmest solution was logging the requests. Here we paste the nginx log format we used to after be able to replay our user requests:
```
log_format requestlog '$status $time_iso8601 $cookie_PHPSESSID $cookie_opcode "$request" "$request_body"';
```
- $status: Response status, it will be useful to know if the status remains the same, if one request had failed it has to still fail, if it was redirected it has to still do it.
- $time_iso8601: Time of the response, it will help us to know if a certain request drastically decreased its performance, so we would need to investigate.
- $cookie_PHPSESSID: User cookie ID, it provides us information about the status of each user session, so we can simulate accurately the status of connection at the time each user does a request.
- $cookie_opcode: Identifier code of each user, to know which database each request correspond to.
- $request: Path of the request
- $request_body: Params to be send so request is actually the same.
One day we stopped our app traffic for few minutes, setting up the new log_format into a new log file, creating a snapshot of the server which includes: databases backups(one per user) and client php session files, every file under /var/log/php. After two days we repeat the process to get the new backup of databases so we can use them to compare if our replaying process is successful or not.
Replay traffic across both app versions
Using logs obtained at the previous step, we replayed every request, first only replaying traffic from one client and once you get all its request a full match in the outputs then you replay for all of them at same time.
For that you have to keep in mind to bear the each user session in a separate process because requests can belong to different users, even if they all belong to the same client, so we stored each of the COOKIE_ID separately so sessions don’t get mess up, for that you can use CookieJar from the Cookielib of Python, which keep sessions up to date request after request and allows you to reproduce traffic with same flow than originally.
Compare outputs
During this step we faced a lot of issues, it wasn’t only a matter of reading every exception at the logs and going to straight to that and fix it. The main issue was how to obtain exactly the same output for the html views, and how to compare them and highlight only the differences. For that we needed to implement a separated tool based on BeautifulSoup library of Python and extending its normal use to take only differences. This was one of the outputs of that tool:
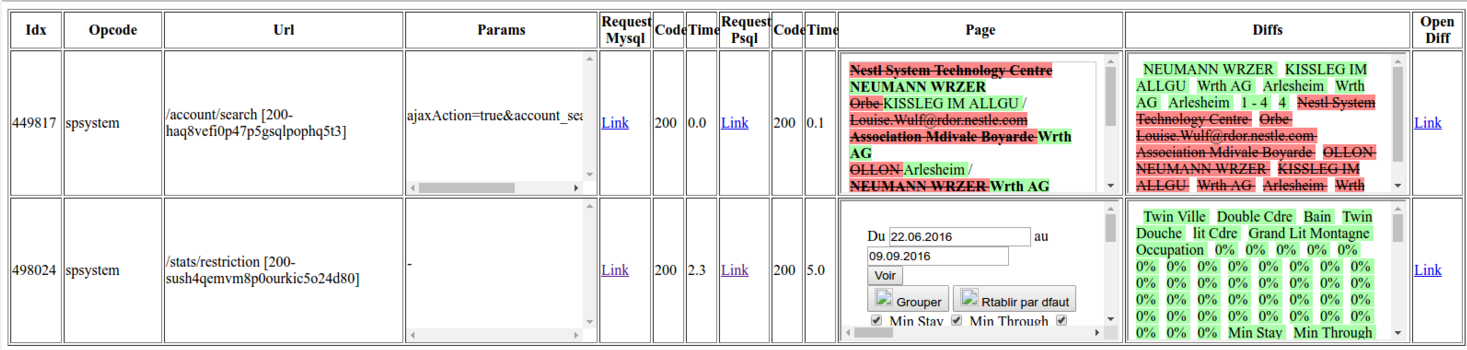
Compare final status of databases
For this step we reused the tool we implemented before to compare databases to see if everything is still in the same status on both version of the app, MySQL and Postgres. This step made us realized, in between many others, dates weren’t saved with the right time (UTF) even if the server was already running on UTC, at the end it was a project setting options related to the client timezones.
Step3: Speed up migration process
Now it was time to prepare the final launch of Postgres. So far everything went well but we were only testing few client databases and on a narrow scope from what it was going to be the real and final launching.
First of all, we hired a new dedicated server at the same company we have the main one, this new server was going to be become our new live server, becoming at same time the old one the next backup server.
On this new server we replicated the same settings we had in the live server, restoring the snapshots(backup database and php session files) taken during the prior phase. Apart of that we took advantage of the process to install a passwordless environment where every connection would be based on certificates, sockets and whitelisted ips. As last step we imported our implemented migration tools then it was time to run them on a full real environment.
These were the conclusions produced from running our implemented tools on a real environment:
- Migrate process was taking around 3-4 hours to complete.
- Validating if data was exported correctly, was endless.
- Replaying traffic for every client, after 24h running didn’t even reach even 10% of the total.
Derived from those facts we took the decision of parallelism every step which could ran in parallel for each of those processes, about all, we were concerned of the first of them, because we won’t be able to afford a 3-4 hours downtime in our servers, taking in account we were going to need to do some more maintenance tasks after migration was completed, on top of it, move cronjobs, redirect app domains and restart services, all of that should be within an hour. So it was time to work again.
As we just said above, our main challenge was improving the performance of the migration script to get those 1200 databases into Postgres in the minimum amount of time, definitely it had to be less than 1 hour.
There are two concepts we had to apply here to improve performance:
- Multithreading: It is the ability of a central processing unit (CPU) or a single core to execute multiple processes or threads concurrently using shared memory for it.
- Multiprocessing: It is the use of two or more central processing units (CPUs) within a single computer system without shared memory.
According to the description above, we used Multiprocessing to split databases migrations, each database was going to run in a single and separated CPU. That was clear and easy to implement. Now we have to find out how to take advantage of the Multithreading, these were every step we were running to complete a single database migration, all of them were running sequentially and we needed to parallelism them.
Sequential Version:
Parallel Version:
As a result from previous improvement we were able to import every client database in less than 30 minutes, YUHU !!!! Then we got motivated from such a improvement and we decided to try go deeper in code and identify which were the heaviest computing pieces and work on them to improve it. Thanks to it we pointed few loops to where we were able to reduce the number of iterations and another few parsing methods were running unnecessarily and were consuming a lot of cycles. Moreover we came across a bottleneck at the disk I/O, so we decided to upgrade our server with a SSD.
Here there is an screenshot of the status of our server meanwhile we were running the script:

In conclusion from all previous improvements we reduced the computing time of our migration script from 3 hours to 9 minutes, that is a 6000% faster. We got kind of the same results on the rest of the tools. So now we were ready to the moment of truth.
Step4: The moment of Truth
After around 2 months working on it, we decided to move forward with the Postgres migration. This migration wasn’t going to involve only a new simple release, we were also going to migrate servers because we were setting up new domains, services and dependencies for Postgres in a server, that way we didn’t affect the normal use of our product and clients.
Aiming to have a easy backup plan in case things are not going as expected, we decided to prepare a plan B to restore original server in case migration is not going as expected. That plan B was the following one:
- Proxy traffic from former server to new server, instead of modifying DNS to point to the new server IP, that way we could always re-enable the previous version instantly.
- Log every single request in the replayable mode therefore we have the opportunity to reproduce the traffic onto former version of the product once we restore it.
- Create an snapshot of the server before shutting it down, so we restore it at the same point once we re-enable for original version of the app.
We informed our clients that we were going to have a maintenance downtime in the system for around an hour in 3th of July at 03.00AM(UTC+2) therefore we reduced the impact of normal use of our app to our clients, due to, even if we have clients from everywhere around the world, most of them are located in Europe.
During the day D, we all met around 16.00, we were doing a final testing, mostly manual testing, playing around the tool trying to find glitches derived from the migration, we found a bunch amount of them, luckily they were mostly UX issues, and easy to fix. At the same time we were preparing a set of scripts to run in sequence to cover the whole migration, that way we didn’t leave anything to the chance. The scripts we prepare were:
- Script 1: Cleans every testing data from new server and re-installing every db package from scratch.
- Script 2: Shuts down the live server, running a full back of every client and copying data to new server.
- Script 3: Triggers the migrations scripts, posteriori data validation and summarizing logs in easy readable way for us.
- Script 4: Enabling proxies to redirect traffic from former server to new server.
Time to release came and after a couple hours break we were ready to proceed with the migration, script_1 is launched, script_2 running during a long while....script_3 !!! critical moment just began, those 8 minutes were the slowest ones of my career as developer, few errors came up but not major issues we were going to check it later, then script_4 and time to monitor every application logs: proxies were performing well, traffic was coming into new server normally, a quick manual test on the application, everything was looking good, after checking the import logs we realized we got issues on one client but fortunately it was not active anymore, so nothing to worry. After few more minutes, till an hour couple of exceptions came up, we did couple of hotfixes and releases, but not major issues. WE DID HAVE GO IT!!! We went back home to sleep a bit we had got it.
For sure, nothing can go so well in real live. Three hours after we got into bed our phones started ringing. Application wasn’t accessible,we didn’t know what was happening, server was not reachable, nothing was working To sum up, the issue wasn’t part of our migration, at all, but we got bad luck but that will probably be part of another post.
As of today we are running with Postgres, we got a 30% average speed up in out time responses, we have postgres replication running across two servers what allows us to an alternative access in case of failover. We implemented two new schemas with triggers and procedures written in plv8(include link) whose performance allow us to have historical information about our client changes and many more things on the way running all across Postgres.
I hope you enjoyed the read and have learnt something from it.
For future reference this may solve some of your steps above: https://github.com/seanharr11/etlalchemy
ReplyDeletePostgres have JSONB columns, this approach is usually good for data that change a lot and are difficult to normalize.
ReplyDeleteCorrection: Gor/goreplay does not sit in between the client and the server handling the request. It uses libpcap to unintrusively listen to network packets, and as such should be safe to use in a production environment without interfering. We've been running it on multiple production machines for weeks now and haven't had any issues.
ReplyDeleteYou might want to have a look at http://pgloader.io which implements a fully automated migration process. The work is done in a parallel fashion, much like what you describe here, with some clever tricks for doing all the indexes in parallel, including pk indexes.
ReplyDeleteAmazing information on Mysql. It’s really unique and valuable also. It gives me lots of pleasure and interest. Thanks a lot for sharing the amazing and outstanding post on public. Clipping Path | Shadow Creation | Vector Conversion | Product Photo Editing
ReplyDeleteThank you so much for sharing these nice articles
ReplyDeleteYour blog was so nice...http://clippingpathindie.com/
Thanks for your nice posting.
ReplyDeletehttps://www.graphic-aid.com/background-removing
https://www.graphic-aid.com/photo-masking-service
https://www.graphic-aid.com/clipping-path
https://www.graphic-aid.com/
https://www.graphic-aid.com/neck-joint-service
Hi, Very good article on Migrating 1200 db from Mysql to Postgres,
ReplyDeleteThanks for sharing, keep up the good work.
Photoshop Clipping Path | Web Images Optimization | Images Background Remove | Natural Drop Shadow | Raster to Vector Conversion | Contact Us
wow..that will be great...
ReplyDeleteHey!! Amazing post. Thank you for sharing such a informative post.
ReplyDeletePhoto Retouching Services
perde modelleri
ReplyDeleteSms onay
mobil ödeme bozdurma
nft nasıl alınır
ANKARA EVDEN EVE NAKLİYAT
trafik sigortası
dedektör
Web Sitesi Kurmak
aşk kitapları